PageRank
Hi, here I’m explaining to you about the Page Ranking and the algorithm of it;
What is Page Ranking (PR)?
 Page Ranking is a link analysis algorithm and it assigns a numerical weighting to each element of a hyperlinked set of documents, such as the World Wide Web, with the purpose of “ measuring ” its relative importance with the set. The algorithm may be applied to any collection of entities with reciprocal quotations and references. The numerical weight that it assigns to any given element E is referred to as the PageRank of E and denoted(meant) by PR(E). Other factors like Author Rank can contribute to the importance of an entity.
Page Ranking is a link analysis algorithm and it assigns a numerical weighting to each element of a hyperlinked set of documents, such as the World Wide Web, with the purpose of “ measuring ” its relative importance with the set. The algorithm may be applied to any collection of entities with reciprocal quotations and references. The numerical weight that it assigns to any given element E is referred to as the PageRank of E and denoted(meant) by PR(E). Other factors like Author Rank can contribute to the importance of an entity.
PageRank(PR) is an algorithm used by Google Search to rank websites in their search engine results. PageRank was named after Larry Page, one of the founders of Google. PageRank is a way of measuring the importance of website pages. According to Google:
PageRank works by counting the number and quality of links to a page to determine a rough estimate of how important the website is. The underlying are links from other websites.
It is not the only algorithm used by Google to order search results, but it is the first algorithm that was used by the company, and it is the best-known.

Here now you know what is PR about, Ok now we have to move on what is the algorithm of PageRank.
I’m going to explain this you from an example to get you an idea about the PR algorithm.….... 
Assume that there is a creation of four web pages called: A, B, C & D. Linked from C to A, B to A & D to A.

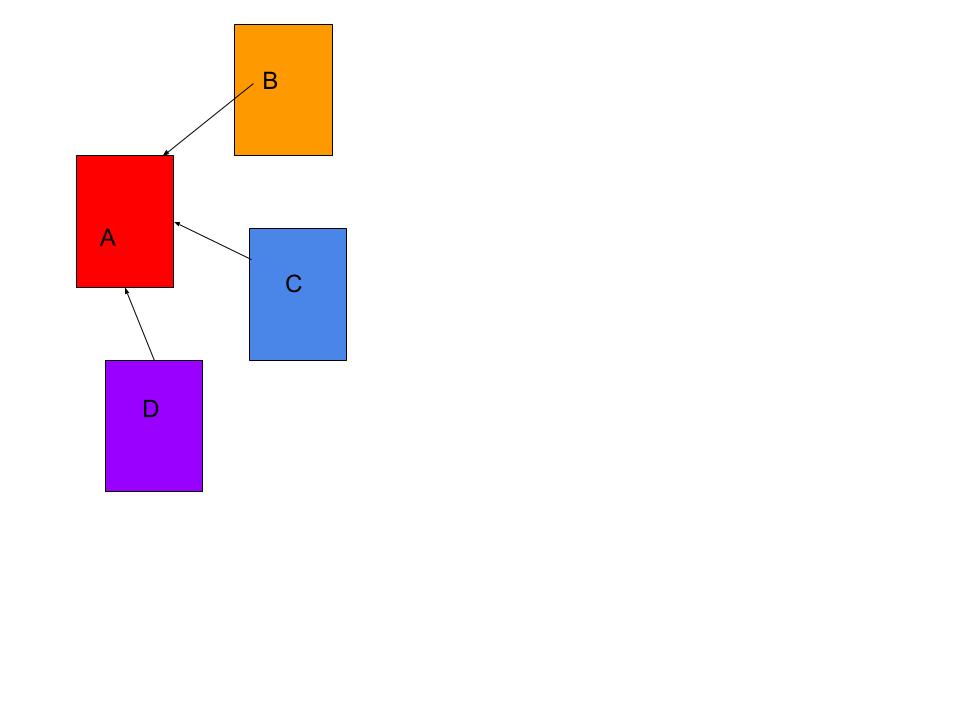
PageRank is initialized to the same value for all pages. In the original form of PageRank, the sum of PageRank over all pages was the total number of pages on the on the web at that time, so that the value of the sum is 1. The probability distribution is between 0 and 1. Hence the initial value for each page in this example is 0.25.
The PageRank transferred from a given page to the targets of its outbound links upon the next iteration is divided equally among all outbound links.
If the only links in the system were from pages B, C, and D to A, each link would transfer 0.25 PageRank to A upon the next iteration, for a total of 0.75.

How to get this 0.75 for Page A ;
Yeh, it is easy, look at the graph below,

PR(A) = PR(B) + PR(C) + PR(D)
Okay let’s take another example,
Suppose instead that page B had a link to pages C and A, page C had a link to page A, and page D had links to all three pages.
Upon the first iteration, page B would transfer half of its existing value, (0.25 / 2); 0.125, to the page A and the other half 0.125 to page C.
Page C would transfer all of its existing value 0.25 to the only page A, hence it has linked only to page A.
Page D had 3 outbound links and it transfers its existing value (0.25/3); 0.083 to page A.
At last of this iteration, Page A will have a PageRank of 0.458 ( 0.083+0.125+0.25).
PR(A) = [PR(B) / 2 ] + [PR(c) / 1 ] + [PR(D) / 3 ]
And here the PR scores for each web pages are;
A= 0.458
B= 0.083
C= 0.208
D= 0
So in the first page, Page A will be the highest rank and then C, B, & D the respectively.
In other words, PR can be expressed as below;
PR(A) = PR(B) /L(B) + PR(C) /L(C) + PR(D) /L(D)
Here the PageRank score of a page is divided by the number of outbound links(L).
Now I think that you got the idea 
Here is the calculation of the PageRank;
def pagerank(G, alpha=0.85, personalization=None,
max_iter=100, tol=1.0e-6, nstart=None, weight='weight',
dangling=None):
" " "Return the PageRank of the nodes in the graph.
PageRank computes a ranking of the nodes in the graph G based on the structure of the incoming links. It was originally designed as an algorithm to rank web pages.
Parameters
----------
G: graph
A NetworkX graph. Undirected graphs will be converted to a directed
the graph with two directed edges for each undirected edge.
alpha: float, optional
Damping parameter for PageRank, default=0.85.
personalization: dict, optional
The "personalization vector" consisting of a dictionary with a
key for every graph node and nonzero personalization value for each node.
By default, a uniform distribution is used.
max_iter : integer, optional
The maximum number of iterations in the power method eigenvalue solver.
tol : float, optional
Error tolerance used to check convergence in power method solver.
nstart : dictionary, optional
Starting value of PageRank iteration for each node.
weight: key, optional
Edge data key to use as the weight. If None weights are set to 1.
dangling: dict, optional
The outedges to be assigned to any "dangling" nodes, i.e., nodes without any outedges. The dict key is the node the outedge points to and the dict
value is the weight of that outedge. By default, dangling nodes are given outedges according to the personalization vector (uniform if not
specified). This must be selected to result in an irreducible transition matrix (see notes under google_matrix). It may be common to have the dangling dict to be the same as the personalization dict.
Returns
-------
pagerank : dictionary
Dictionary of nodes with PageRank as the value
Notes
The eigenvector calculation is done by the power iteration method and has no guarantee of convergence. The iteration will stop
at stop after max_iter iterations or an error tolerance of
number_of_nodes(G)*tol has been reached.
The PageRank algorithm was designed for directed graphs but this
the algorithm does not check if the input graph is directed and will
execute on undirected graphs by converting each edge in the
directed graph to two edges.
"""
if len(G) == 0:
return {}
if not G.is_directed():
D = G.to_directed()
else:
D = G
# Create a copy in (right) stochastic form
W = nx.stochastic_graph(D, weight=weight)
N = W.number_of_nodes()
# Choose fixed starting vector if not given
if nstart is None:
x = dict.fromkeys(W, 1.0 / N)
else:
# Normalized nstart vector
s = float(sum(nstart.values()))
x = dict((k, v / s) for k, v in nstart.items())
if personalization is None:
# Assign uniform personalization vector if not given
p = dict.fromkeys(W, 1.0 / N)
else:
missing = set(G) - set(personalization)
if missing:
raise NetworkXError('Personalization dictionary '
'must have a value for every node. '
'Missing nodes %s' % missing)
s = float(sum(personalization.values()))
p = dict((k, v / s) for k, v in personalization.items())
if dangling is None:
# Use personalization vector if dangling vector not specified
dangling_weights = p
else:
missing = set(G) - set(dangling)
if missing:
raise NetworkXError('Dangling node dictionary '
'must have a value for every node. '
'Missing nodes %s' % missing)
s = float(sum(dangling.values()))
dangling_weights = dict((k, v/s) for k, v in dangling.items())
dangling_nodes = [n for n in W if W.out_degree(n, weight=weight) == 0.0]
# power iteration: make up to max_iter iterations
for _ in range(max_iter):
xlast = x
x = dict.fromkeys(xlast.keys(), 0)
danglesum = alpha * sum(xlast[n] for n in dangling_nodes)
for n in x:
# this matrix multiply looks odd because it is
# doing a left multiply x^T=xlast^T*W
for nbr in W[n]:
x[nbr] += alpha * xlast[n] * W[n][nbr][weight]
x[n] += danglesum * dangling_weights[n] + (1.0 - alpha) * p[n]
# check convergence, l1 norm
err = sum([abs(x[n] - xlast[n]) for n in x])
if err < N*tol:
return x
raise NetworkXError('pagerank: power iteration failed to converge ' ‘ in %d iterations.' % max_iter)
The above code is the function which has been implemented in the networkx library.
To implement the above in networkx, you will have to do the following:
>>> import networkx as nx
>>> G=nx.barabasi_albert_graph(60,41)
>>> pr=nx.pagerank(G,0.4)
>>> pr
Reference :
Thank You!
sanduniisa

Good work !!!keep it on
ReplyDeleteGood job Sanduni...
ReplyDelete